Introduction
In this post, I will explain the initial approach you can take when you need to enumerate an organization in an environment where you have zero knowledge of the target organization. This guide focuses on practical, real-world techniques that I've found effective in my experience.
⚠️ Disclaimer ⚠️
1.Don't rely solely on Automation - The best and most critical bugs come through manual exploitation. In my humble opinion, there's no black magic, and don't think that by launching Nuclei or any other tool at 20k domains you're going to find any significant bugs.
2.The techniques we'll describe in this blog don't cover the entire scope of an organization - this is a first approach to enumerate special assets.
- In future blogs, I'll write about other methods I consider very useful that add a lot of value to an organization scan, and we'll also cover Cloud Environment.
3.In my opinion, having strong knowledge of how to enumerate, study, and interpret tool output in the enumeration stage is ESSENTIAL and will allow you to find potential hidden entry vectors and expand the attack surface in a pentest, red team exercise, or bug bounty program.
4.In this blog, I won't cover ways to bypass WAFs, favicon enum, dorks etc. (we'll leave that for a future blog 😘)
ASN Enumeration
What is an ASN?
An Autonomous System (AS) is a network or group of networks under a single administrative entity that follows a common routing policy. Each AS is assigned a unique Autonomous System Number (ASN) to identify it on the internet and facilitate global routing.
⚠️ Important Note: We will not always be able to enumerate the ASNs of an organization since many companies don't have their "own" infrastructure and use ASNs provided by third parties such as Amazon, Google, etc.
ASN Discovery Process
When facing an organization in a Red Team or Bug Bounty program without a defined scope or wildcard domains, but with the whole organization to enumerate from scratch, I like to start by checking if the company has its own ASNs.
To enumerate these systems, I like to use several different methods and compare their results:
- Using amass:
BASH$ amass intel -org "Apple Inc"
- Manual checks with:
Example: Apple Inc. ASN Enumeration
Let's look at a real example with Apple Inc.:
-
amass returned only 2 results:
- ASN: 6185 - APPLE-AUSTIN - Apple Inc.
- ASN: 714 - APPLE-ENGINEERING - Apple Inc.
-
From bgpview.io we got 3 results:
- ASN: 1036
- ASN: 1042
- ASN: 714
-
From bgp.he.net we got 5 hits:
- AS714
- AS6185
- AS2709
- AS1042
- AS1036
After combining and removing duplicates, we have 5 unique ASNs.
Pro Tip: In my experience, bgp.he.net usually provides the most complete results, but I always recommend checking different sources - you never know what might appear.
IP Range Extraction
Initial Setup
Once we have the ASNs, we extract the associated IP ranges. Here's a simple bash script I use:

Click to expand
ASN extraction script
From these ASNs, I obtained 2,238 different ranges. This presents both opportunities and challenges:
- We need to identify which ranges might be out of scope
- We don't have any domains or subdomains yet, so we must associate and identify these using the IP ranges
Using mapcidr
I like to use mapcidr from Project Discovery (huge kudos to these guys for making such awesome tools accessible):
BASH$ mapcidr -cl apple_ip_ranges.txt -silent -o cidr_apple_ranges.txt
This gives us 59,078,144 IPs:
BASHcat cidr_apple_ranges.txt | wc -l 59078144
While it's impossible to check each IP individually, this information becomes valuable when we have domains, subdomains, and vhosts to work with, allowing us to enumerate more information by fuzzing the Host header.
Domain Discovery
Reverse WHOIS
The WhoisXMLAPI API is my go-to tool for initial domain discovery. While it's a paid service, you get 500 free queries per month which can be sufficient for initial reconnaissance. Here's how to use it:
BASH$ curl --location 'https://reverse-whois.whoisxmlapi.com/api/v2' \ --header 'Content-Type: application/json' \ --data '{ "apiKey": "[...SNIP...]", "searchType": "current", "mode": "purchase", "punycode": true, "responseFormat": "json", "includeAuditDates": true, "basicSearchTerms": { "include": [ "Apple, Inc." ] } }' -o apple_reverse_whois_domains.json
Parse the results to get a clean list of domains:
BASH$ jq -r '.domainsList[].domainName' apple_reverse_whois_domains.json | domainparser | sort -u | tee apple_domains.txt $ cat apple_domains.txt | wc -l 9976
SSL Certificate Transparency Logs
Certificate Transparency (CT) logs are an excellent source for discovering domains. Here's how it works:
- When an SSL/TLS certificate is issued, it is recorded in the CT logs
- The certificate receives a Signed Certificate Timestamp (SCT)
- Browsers verify this SCT when visiting websites
I usually use crt.sh for this situation in two ways:
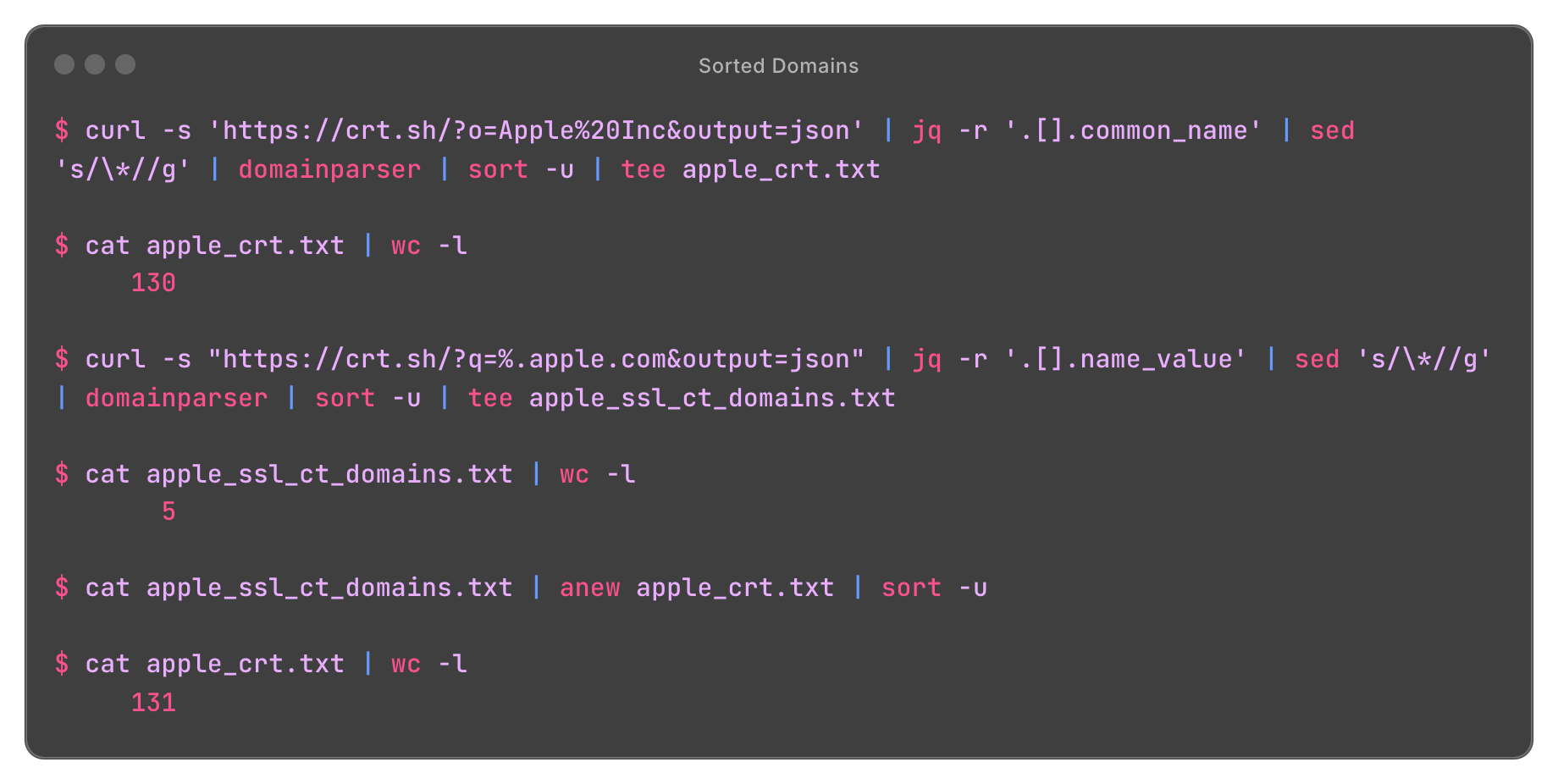
- Organization-based search:
BASH$ curl -s 'https://crt.sh/?o=Apple%20Inc&output=json' | jq -r '.[].common_name' | sed 's/\*//g' | domainparser | sort -u | tee apple_crt.txt
- Domain pattern search:
BASH$ curl -s "https://crt.sh/?q=%.apple.com&output=json" | jq -r '.[].name_value' | sed 's/\*//g' | domainparser | sort -u | tee apple_ssl_ct_domains.txt
Click to expand
crth
AI-Assisted Discovery
AI tools like ChatGPT and Perplexity can help identify additional domains that might be missed through traditional enumeration. For example, they might suggest domains like icloud.com or iwork.com that are part of the target organization but might not be immediately obvious.
Using these tools, I discovered an additional 127 domains:
BASH$ cat perplexity_domains.txt | wc -l 127
Domain Filtering
After combining all sources, we had 14,305 domains:
BASH$ cat all_domains.txt | wc -l 14305
This is too many to work with effectively, so we need to filter them. First, let's check which ones actually resolve:
BASH$ cat all_filtered_domains.txt | dnsx -silent -a -r /path/to/resolvers.txt | tee resolver_tlds_valid_subdomains.txt $ cat resolver_tlds_valid_subdomains.txt | wc -l 1473
Filtering domains
We have reduced the domains from 14k to 1473, making it much more manageable. Although automation is helpful, we can filter the data further since many domains originate from the root domain apple.com. I typically use two approaches: AI with nabuu for filtering web hosts, and HTTP Probing technique, which I'll explain later in the blog.
- I've created two GitHub scripts that validate domains by comparing either ASN or NS records. This helps eliminate false positives and clean up domains that don't actually belong to the organization.
- Important note: When using ASN comparison, remember that some domains may have active DNS records for the organization but lack an A (IP) record because they're unused or defunct.
- AI is particularly valuable here for quickly identifying and elevating an organization's root domains. For example, Perplexity provided the following results for Apple Inc.
 Click to expand
Click to expandPerplexity
Reverse DNS Enumeration
⚠️ Note: This is one of the best techniques for finding potential and sensitive subdomains of an organization, but it has a significant drawback when working with organizations with many ranges and IPs as it is very time-consuming.
Benefits
- If we have an IP range from ASN lookup, we can check if any IPs map back to hostnames
- This often reveals hidden subdomains that weren't found via normal enumeration
Tools and Techniques
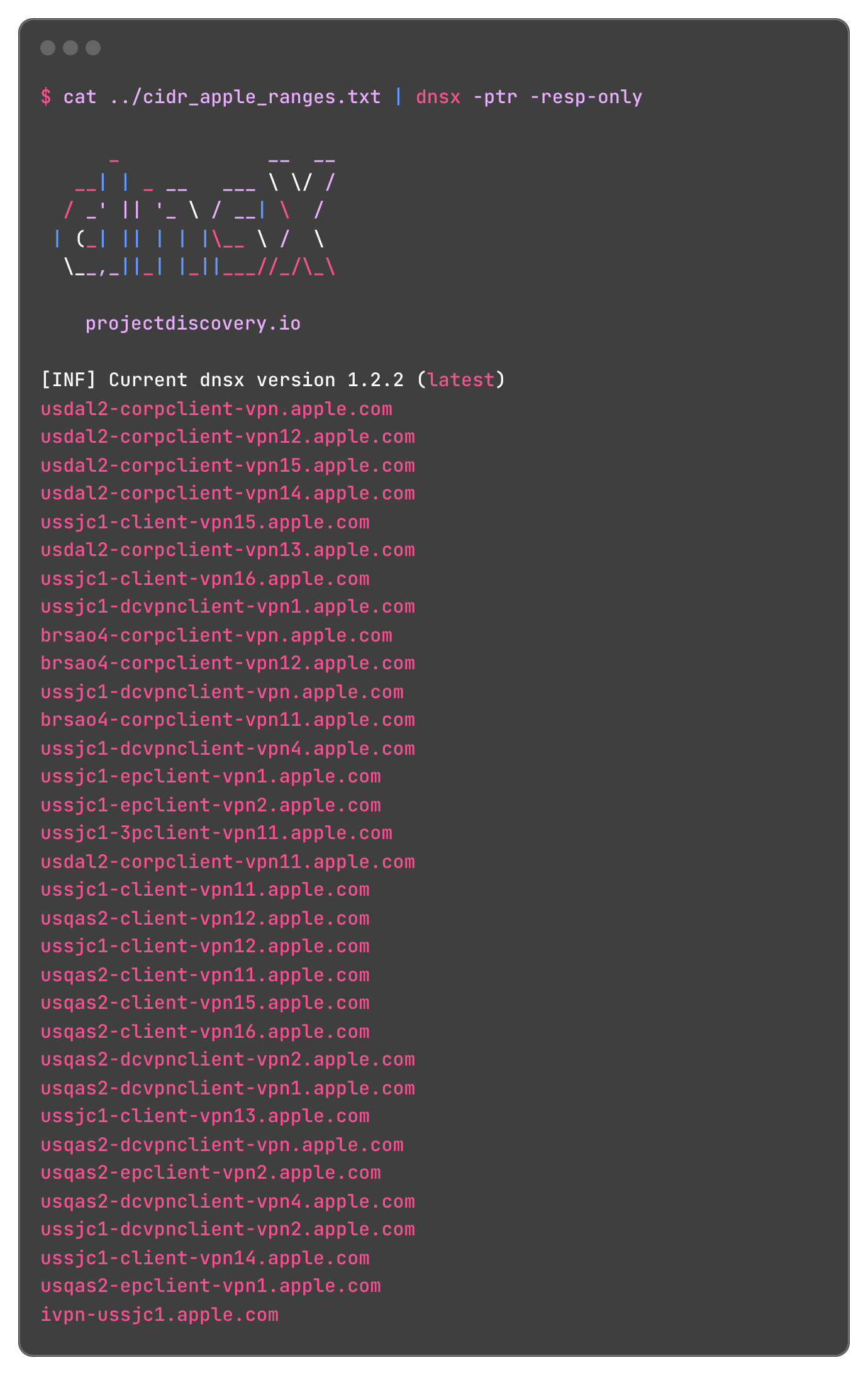
- Using dnsx:
BASH$ cat ../apple_ip_ranges.txt | mapcidr | dnsx -ptr -resp-only
Click to expand
Perplexity
- Using massdns:
BASH$ massdns -r /path/to/resolvers.txt -t PTR -o S -w reverse_dns_results.txt asn_list.txt
- Using zdns:
BASH$ zdns PTR --input-file=ip_list.txt --output-file=zdns_results.txt
Subdomain Enumeration using GitHub
GitHub is a goldmine for subdomain enumeration. By searching for specific keywords, we can find repositories that contain sensitive information, including subdomains. I like to use the github-subdomains tool for this task.
Link to the tool: github-subdomains -> Author: gwen001
BASH$ github-subdomains -d apple.com ▗▐ ▌ ▌ ▌ ▌ ▗ ▞▀▌▄▜▀ ▛▀▖▌ ▌▛▀▖ ▞▀▘▌ ▌▛▀▖▞▀▌▞▀▖▛▚▀▖▝▀▖▄ ▛▀▖▞▀▘ ▚▄▌▐▐ ▖▌ ▌▌ ▌▌ ▌ ▝▀▖▌ ▌▌ ▌▌ ▌▌ ▌▌▐ ▌▞▀▌▐ ▌ ▌▝▀▖ ▗▄▘▀▘▀ ▘ ▘▝▀▘▀▀ ▀▀ ▝▀▘▀▀ ▝▀▘▝▀ ▘▝ ▘▝▀▘▀▘▘ ▘▀▀ by @gwendallecoguic [11:09:44] Domain:apple.com, Output:/Users/carlosgomez/Documents/IOActice/Engagements/2025/Therefore/scans/apple.com.txt [11:09:44] Tokens:2, Delay:1200ms [11:09:44] Token rehab:true, Quick mode:false [11:09:44] Languages:20, Noise:7 [11:09:44] keyword:%22apple.com%22, sort:indexed, order:desc, language:, noise:[] [11:09:46] https://api.github.com/search/code?per_page=100&s=indexed&type=Code&o=desc&q=%22apple.com%22&page=1 [11:09:47] current search returned 340800 results, language filter added for later search [11:09:47] https://github.com/AuthorShin/Blocklist_Pi_Hole/blob/cf3e15b77a212b2fa8e3aba64ddd4ab5971f1148/etc.txt [11:09:47] supportmetrics.apple.com [11:09:47] https://github.com/xiaolai/reborn/blob/fb9284feba3982e7e9525ea50390f5708653b284/A09.md [11:09:47] itunes.apple.com [11:09:47] apple.com [11:09:47] https://github.com/HxnDev/Implementing-a-DNS-Server/blob/a3c922f34bcf4b03389561b85e53f3f3eff772f8/dns.txt [11:09:47] www.apple.com [...SNIP...] [11:11:31] 21 searches performed [11:11:31] 209 subdomains found
Passive Subdomain Enumeration
Passive subdomain enumeration efficiently gathers information about a target without direct interaction. This process analyzes publicly available data and third-party resources—including DNS records, SSL/TLS certificate logs, and web archives like Wayback Machine—to discover subdomains. This approach allows us to collect historical data without generating suspicious traffic to the target.
For this task, I prefer to combine results from two powerful tools.
Since each tool deserves its own detailed post, I'll focus on their most important features.
- bbot → The first tool is a comprehensive framework that goes beyond subdomain enumeration. It supports various recon tasks and bug bounty workflows, featuring spidering modules and integration with tools like nuclei, ffuf, and nmap.
- Subfinder → developed by ProjectDiscovery, is a DNS enumeration tool with versatile output formatting. This flexibility makes it easy to integrate results with other security tools and generate detailed reports.
Both tools support multiple API configurations, enabling broader and more comprehensive subdomain searches.
Bbot → https://www.blacklanternsecurity.com/bbot/Stable/modules/list_of_modules/
 Subfinder → https://docs.projectdiscovery.io/tools/subfinder/install#post-install-configuration
Subfinder → https://docs.projectdiscovery.io/tools/subfinder/install#post-install-configuration

Click to expand
bbot
Click to expand
subfinder
Tools
For an average-scope project, I typically start with these two commands (though their effectiveness depends on how many tool APIs you've taken the time to configure 😅).
- BBOt (github.com/blacklanternsecurity/bbot)
- Complete framework for reconnaissance
- Supports multiple modules including spidering, nuclei, ffuf, nmap etc
Basic usage:
BASH$ bbot -t <list>.txt -p subdomain-enum -m baddns urlscan virustotal shodan_dns binaryedge censys
- Subfinder (github.com/projectdiscovery/subfinder)
- Efficient DNS enumeration tool
- Excellent output formatting capabilities
- Easy integration with other tools
Basic usage:
BASH$ subfinder -dL <list>.txt -all -o <list>.txt -v | dnsx
- Amass (github.com/owasp-amass/amass)
- Comprehensive information gathering tool
- Multiple data sources and techniques
BASH$ amass enum -d apple.com -o apple.txt
HTTP Probing
The final step is validating which domains are actually serving web content. HTTP probing helps eliminate false positives from your collected domains by verifying which ones actively serve web content. This verification is crucial since many gathered domains may be inactive.
I won't delve into exhaustive details here, as this topic deserves its own article—which I plan to write later. Instead, I'll outline the basic steps for HTTP probing using the httpx tool from Project Discovery.
I typically start with the -probe flag, which quickly filters requests between [SUCCESS] and [FAILED] statuses.
BASH# First resolve all domains $ cat <domain_list>.txt | dnsx -silent -a -r /path/to/resolvers.txt | tee <domain_list_resolver>.txt # Probe multiple ports $ cat <domain_list_resolver>.txt | httpx -probe -ports "22,80,443,1337,2375,2376,3000,3001,3002,3003,3306,4000,4001,4002,4200,4443,5000,5173,5432,5601,6379,8000,8080,8081,8082,8083,8443,8888,9000,9001,9090,9200,10250,27017,50000" | tee debug_httpx.txt # Filter successful requests without the protocol $ cat debug_httpx.txt | grep "SUCCESS" | awk '{gsub(/^https?:\/\//, "", $1); print $1}' > success_domains.txt # Filter successful requests with the protocol $ cat debug_httpx.txt | grep "SUCCESS" | awk '{print $1}' > success_domains_with_protocol.txt
Once we have the list of domains with web content, we should analyze their response codes (404, 302, 301, 200, etc.) to further refine our target list. For Red Team exercises or bug bounty programs, don't limit yourself to just 200 responses - other status codes might reveal interesting attack vectors.
Advanced HTTP Probing
For more detailed analysis, I use these httpx flags:
- -silent - Silent mode
- -status-code - Display response status code
- -tech-detect - Show technologies (based on Wappalyzer)
- -title - Show page titles
- -fr - Follow redirects
- -ss - Take screenshots (useful for later analysis)
BASH$ cat <domain_list_resolver>.txt | httpx -probe -silent -status-code -tech-detect -title -fr -ss -ports "22,80,443,1337,2375,2376,3000,3001,3002,3003,3306,4000,4001,4002,4200,4443,5000,5173,5432,5601,6379,8000,8080,8081,8082,8083,8443,8888,9000,9001,9090,9200,10250,27017,50000" | tee debug_httpx.txt
Conclusion
Reconnaissance is a critical phase in any security assessment. The techniques covered in this post provide a solid foundation for initial enumeration of large organizational scopes:
- ASN Enumeration: Helps identify the organization's network infrastructure
- IP Range Extraction: Provides a map of potential target space
- Domain Discovery: Through various methods including WHOIS, SSL certificates, and AI assistance
- Subdomain Enumeration: Both passive and active techniques to expand the attack surface
- HTTP Probing: To validate and categorize discovered assets
Remember that this is just the beginning - effective reconnaissance requires:
- Patience and thoroughness
- Multiple data sources and tools
- Manual verification and analysis
- Continuous refinement of results
- Understanding of the target's infrastructure
The key to successful reconnaissance is not just gathering data, but knowing how to interpret and act on the information collected. Always prioritize quality over quantity and maintain a systematic approach to your enumeration process.